![]()
Qwen-VL 🤖 | 🤗 | Qwen-VL-Chat 🤖 | 🤗 | Qwen-VL-Chat-Int4 🤗
WeChat | Discord | Demo | Paper | Colab | Tutorial
日本語ドキュメントメンテナー: Ikko Eltociear Ashimine
Qwen-VL シリーズの 2 つのモデルを公開します:
- Qwen-VL: LLM の初期化に Qwen-7B を、視覚エンコーダの初期化に [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) を用いた学習済み LVLM モデル。そして、それらをランダムに初期化されたクロスアテンションレイヤーで接続する。
- Qwen-VL-Chat: マルチモーダルな LLM ベースの AI アシスタント。Qwen-VL-Chat は、複数の画像入力、複数ラウンドの質問応答、クリエイティブな機能など、より柔軟なインタラクションをサポートします。
## ニュースとアップデート
* 2023.9.25 Qwen-VL-Chat モデルが更新され、中国語コマンドのフォローがより堅牢になり、Web ページと表の画像の理解と質問と回答の機能が向上し、対話のパフォーマンスが向上しました (タッチストーン: 中国語: 401.2->481.7、英語: 645.2->711.6)。
* 2023.9.12 フルパラメータ微調整、LoRA、Q-LoRA を含む、Qwen-VL モデルの微調整をサポートするようになりました。
* 2023.9.8 [Colab](https://github.com/camenduru/Qwen-VL-Chat-colab) のサンプルを提供してくれた [camenduru](https://github.com/camenduru) に感謝します。これをチュートリアルとして使用して、12G GPU でローカルまたはオンラインのデモを行うことができます。
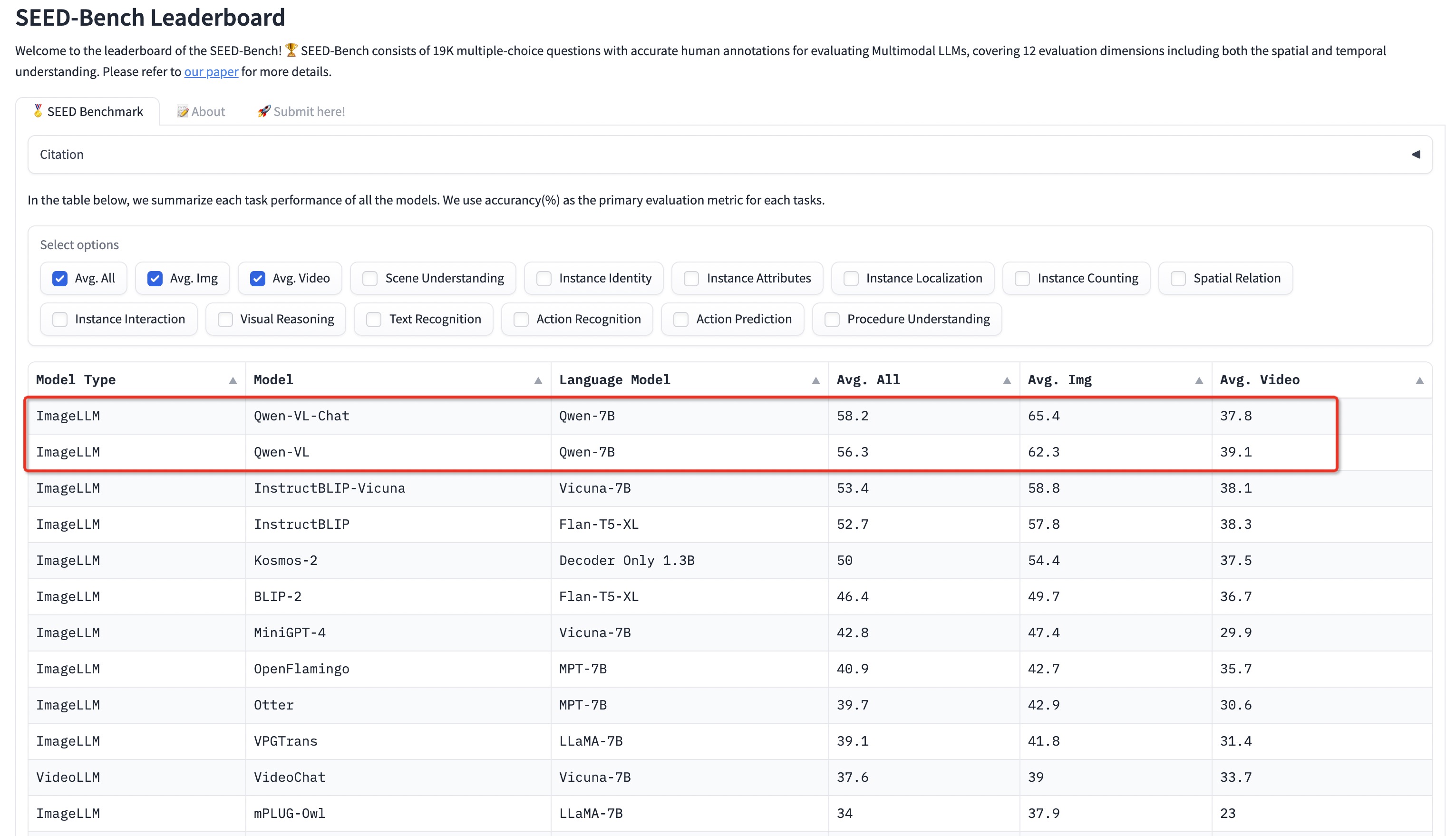
* 2023.9.4 Qwen-VL シリーズは、画像とビデオの両方の理解を含むマルチモーダル LLM を評価するための、正確な人による注釈を備えた 19,000 個の多肢選択質問のマルチモーダル ベンチマークである [Seed-Bench](eval_mm/seed_bench/EVAL_SEED.md) で SOTA を達成します。
* 2023.9.1 基本的な認識と理解だけでなく、文学創作までを含むマルチモーダル言語モデルの包括的な評価である [TouchStone](https://github.com/OFA-Sys/TouchStone) 評価をリリースします 。 強力な LLM を判定者として使用し、マルチモーダルな情報をテキストに変換します。
* 2023.8.31 低メモリコストでありながら推論速度の向上を実現する Qwen-VL-Chat 用の Int4 量子化モデル **Qwen-VL-Chat-Int4** をリリースしました。 また、ベンチマーク評価においても大きなパフォーマンスの低下はありません。
* 2023.8.22 ModelScope と Hugging Face で **Qwen-VL** と **Qwen-VL-Chat** をリリースしました。 また、トレーニングの詳細やモデルのパフォーマンスなど、モデルの詳細については [論文](https://arxiv.org/abs/2308.12966) も提供しています。
## 評価
モデルの能力を2つの観点から評価しました:
1. **標準ベンチマーク**: マルチモーダルなタスクの 4 つの主要カテゴリーについて、モデルの基本的なタスク能力を評価する:
- ゼロショットキャプション: 未見のデータセットに対して、モデルのゼロショット画像キャプション能力を評価する;
- 一般的な VQA: 判定、色、数、カテゴリなど、画像の一般的な質問応答能力を評価する;
- テキストベース VQA: 文書 QA、図表 QAなど、写真内のテキストを認識するモデルの能力を評価する;
- 参照表現理解: 参照表現理解: 参照表現で記述された画像内の対象物を特定する能力を評価する。
2. **TouchStone**: 総合的なテキスト画像対話能力と人間とのアライメントレベルを評価するために、GPT4 によるスコアリングに基づく TouchStone と呼ばれるベンチマークを構築し、LVLM モデルを評価しました。
- TouchStone ベンチマークは、合計 300 以上の画像、800 以上の質問、27 のカテゴリをカバーしています。例えば、属性ベースの Q&A、有名人の認識、詩の作文、複数の画像の要約、商品比較、数学の問題解決などです;
- 画像の直接入力という GPT4 の現在の制限を打ち破るため、TouchStone は人間のラベル付けによるきめ細かい画像注釈を提供します。これらの詳細な注釈は、質問とモデルの出力と共に、採点のために GPT4 に提示されます。
- ベンチマークには英語版と中国語版があります。
評価結果は以下の通りです:
Qwen-VL は、複数の VL タスクにおいて、現行の SOTA ジェネラリストモデルを上回り、また、能力範囲の点でより包括的なカバレッジを持ちます。
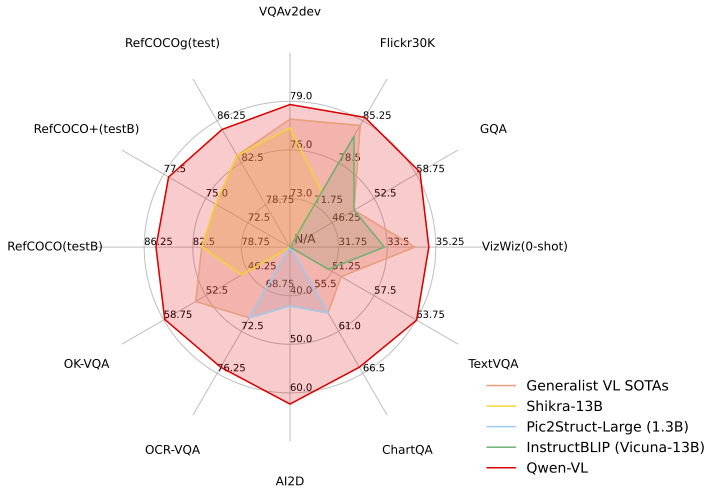
### ゼロショットキャプションと一般的な VQA
| Model type | Model | Zero-shot Captioning | General VQA | |||||
|---|---|---|---|---|---|---|---|---|
| NoCaps | Flickr30K | VQAv2dev | OK-VQA | GQA | SciQA-Img (0-shot) |
VizWiz (0-shot) |
||
| Generalist Models |
Flamingo-9B | - | 61.5 | 51.8 | 44.7 | - | - | 28.8 |
| Flamingo-80B | - | 67.2 | 56.3 | 50.6 | - | - | 31.6 | |
| Unified-IO-XL | 100.0 | - | 77.9 | 54.0 | - | - | - | |
| Kosmos-1 | - | 67.1 | 51.0 | - | - | - | 29.2 | |
| Kosmos-2 | - | 80.5 | 51.1 | - | - | - | - | |
| BLIP-2 (Vicuna-13B) | 103.9 | 71.6 | 65.0 | 45.9 | 32.3 | 61.0 | 19.6 | |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | - | - | 49.5 | 63.1 | 33.4 | |
| Shikra (Vicuna-13B) | - | 73.9 | 77.36 | 47.16 | - | - | - | |
| Qwen-VL (Qwen-7B) | 121.4 | 85.8 | 78.8 | 58.6 | 59.3 | 67.1 | 35.2 | |
| Qwen-VL-Chat | 120.2 | 81.0 | 78.2 | 56.6 | 57.5 | 68.2 | 38.9 | |
| Previous SOTA (Per Task Fine-tuning) |
- | 127.0 (PALI-17B) |
84.5 (InstructBLIP -FlanT5-XL) |
86.1 (PALI-X -55B) |
66.1 (PALI-X -55B) |
72.1 (CFR) |
92.53 (LLaVa+ GPT-4) |
70.9 (PALI-X -55B) |
| Model type | Model | TextVQA | DocVQA | ChartQA | AI2D | OCR-VQA |
|---|---|---|---|---|---|---|
| Generalist Models | BLIP-2 (Vicuna-13B) | 42.4 | - | - | - | - |
| InstructBLIP (Vicuna-13B) | 50.7 | - | - | - | - | |
| mPLUG-DocOwl (LLaMA-7B) | 52.6 | 62.2 | 57.4 | - | - | |
| Pix2Struct-Large (1.3B) | - | 76.6 | 58.6 | 42.1 | 71.3 | |
| Qwen-VL (Qwen-7B) | 63.8 | 65.1 | 65.7 | 62.3 | 75.7 | |
| Specialist SOTAs (Specialist/Finetuned) |
PALI-X-55B (Single-task FT) (Without OCR Pipeline) |
71.44 | 80.0 | 70.0 | 81.2 | 75.0 |
| Model type | Model | RefCOCO | RefCOCO+ | RefCOCOg | GRIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | test-A | test-B | val | test-A | test-B | val-u | test-u | refexp | ||
| Generalist Models | GPV-2 | - | - | - | - | - | - | - | - | 51.50 |
| OFA-L* | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | 61.70 | |
| Unified-IO | - | - | - | - | - | - | - | - | 78.61 | |
| VisionLLM-H | 86.70 | - | - | - | - | - | - | - | ||
| Shikra-7B | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 69.34 | |
| Shikra-13B | 87.83 | 91.11 | 81.81 | 82.89 | 87.79 | 74.41 | 82.64 | 83.16 | 69.03 | |
| Qwen-VL-7B | 89.36 | 92.26 | 85.34 | 83.12 | 88.25 | 77.21 | 85.58 | 85.48 | 78.22 | |
| Qwen-VL-7B-Chat | 88.55 | 92.27 | 84.51 | 82.82 | 88.59 | 76.79 | 85.96 | 86.32 | - | |
| Specialist SOTAs (Specialist/Finetuned) |
G-DINO-L | 90.56 | 93.19 | 88.24 | 82.75 | 88.95 | 75.92 | 86.13 | 87.02 | - |
| UNINEXT-H | 92.64 | 94.33 | 91.46 | 85.24 | 89.63 | 79.79 | 88.73 | 89.37 | - | |
| ONE-PEACE | 92.58 | 94.18 | 89.26 | 88.77 | 92.21 | 83.23 | 89.22 | 89.27 | - | |
## 必要条件
* python 3.8 以上
* pytorch 1.12 以上、2.0 以上を推奨
* CUDA 11.4 以上を推奨(GPU ユーザー向けです)
## クイックスタート
以下では、Qwen-VL と Qwen-VL-Chat を 🤖 ModelScope と 🤗 Transformers とともに使う方法を、簡単な例で示します。
コードを実行する前に、環境のセットアップと必要なパッケージのインストールが済んでいることを 確認してください。上記の要件を満たしていることを確認してから、依存するライブラリをインストールしてください。
```bash
pip install -r requirements.txt
```
これで ModelScope や Transformers を使い始めることができます。ビジョンエンコーダについての詳しい使い方は、[チュートリアル](TUTORIAL_ja.md)を参照してください。
#### 🤗 Transformers
Qwen-VL-Chat を推論に使用するために必要なのは、以下に示す数行のコードを入力することだけです。ただし、**最新のコードを使用していることを確認してください。**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# Note: デフォルトの動作では、インジェクション攻撃防止機能がオフになりました。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# bf16 の使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 の使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# cpu のみの使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# cuda デバイスの使用
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータの指定
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 第 1 回 対話ターン
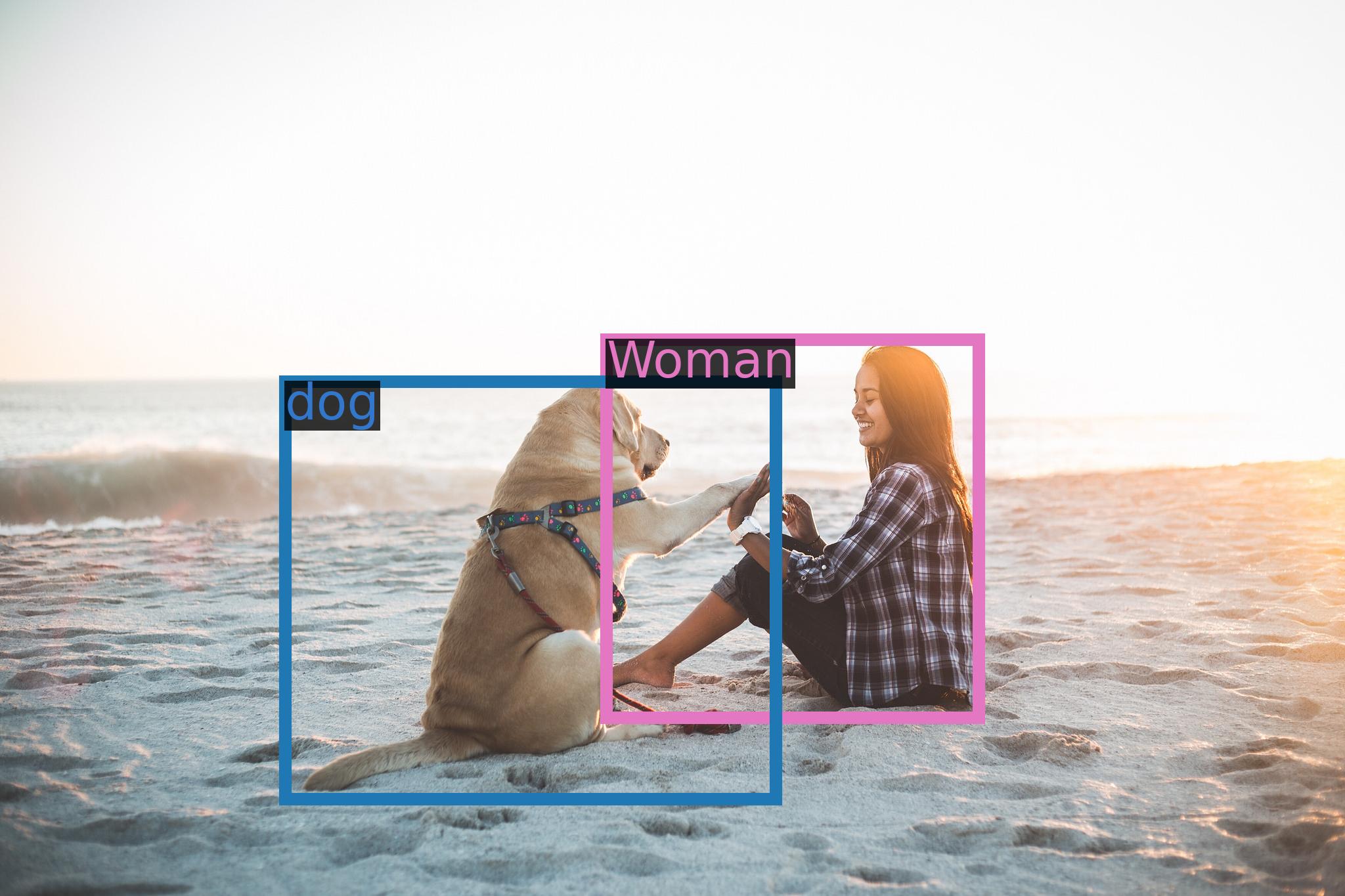
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # ローカルパスまたは url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 写真はビーチでラブラドールの隣で愛犬と戯れる女性が写っており、彼らは砂の中にいる。
# 第 2 回 対話ターン
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# 击掌

HuggingFaceからモデルのチェックポイントとコードをダウンロードする際にネットワークの問題が発生した場合、ModelScopeからチェックポイントをダウンロードする方法はこちらでございます。
```python
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-VL')
model_dir = snapshot_download('qwen/Qwen-VL-Chat')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="cuda",
trust_remote_code=True
).eval()
```
#### 🤖 ModelScope
ModelScope は、MaaS(Model-as-a-Service)のためのオープンソースプラットフォームであり、AI 開発者に柔軟で費用対効果の高いモデルサービスを提供します。同様に、以下のように ModelScope でモデルを実行することができます:
```python
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# bf16 の使用
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 の使用
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# cpu の使用
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# auto の使用
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータの指定
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 第 1 回 対話ターン
# Either a local path or an url between Running Qwen-VL
Running Qwen-VL pretrained base model is also simple.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
# bf16 の使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 の使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
# cpu のみの使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
# cuda デバイスの使用
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータの指定
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # ローカルパスまたは url
{'text': 'Generate the caption in English with grounding:'},
])
inputs = tokenizer(query, return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
print(response)
# https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpegGenerate the caption in English with grounding: Woman
tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
# 写真は、若い女性がビーチで愛犬のラブラドール種と戯れているところ。 二人は浜辺に座り、犬の前脚を上げて触れ合っている。
# 第 2 回 対話ターン
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# "击掌"
## 量子化
### 使用方法
私たちは、[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ)に基づいた新しいソリューションを提供し、Qwen-VL-ChatのためのInt4量子化モデル、Qwen-VL-Chat-Int4[Click here](https://huggingface.co/Qwen/Qwen-VL-Chat-Int4)をリリースします。このモデルは、ほぼ無損失なモデル効果を達成しながら、メモリコストと推論速度の両方のパフォーマンスを向上させます。
ここでは、量子化されたモデルを推論に使用する方法を説明します。始める前に、必要な要件(torch 2.0以上、transformers 4.32.0以上など)を満たしていることを確認し、必要なパッケージをインストールしてください:
```bash
pip install optimum
git clone https://github.com/JustinLin610/AutoGPTQ.git & cd AutoGPTQ
pip install -v .
```
`auto-gptq`のインストールに問題がある場合は、公式の[repo](https://github.com/PanQiWei/AutoGPTQ)をチェックして、ホイールを見つけることをお勧めする。
そうすれば、量子化されたモデルを簡単にロードすることができ、いつもと同じように推論を実行することができる:
```python
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-VL-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
# Either a local path or an url between tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
```
### 性能
ベンチマーク **[TouchStone](https://github.com/OFA-Sys/TouchStone)** において、BF16 モデルと Int4 モデルの両方のモデル性能を例示し、量子化モデルが大きな性能劣化に悩まされないことを見出しました。結果を以下に示します:
| Quantization | ZH | EN |
| ------------ | :--------: | :-----------: |
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
### 推論スピード
BF16 精度と Int4 量子化の下で、画像(258 トークンを要する)のコンテキストで 1792(2048-258)トークンと 7934(8192-258)トークンを生成する平均推論速度(トークン/秒)をそれぞれ測定した。
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
| ------------ | :-----------------: | :-----------------: |
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
プロファイリングは、PyTorch 2.0.1 と CUDA 11.4 を搭載したシングル A100-SXM4-80G GPU で実行されます。
### GPU メモリ使用量
また、1792 (2048-258) 個のトークン (画像を含む) をコンテキストとしてエンコードする場合 (および単一のトークンを生成する場合) と、7934 (8192-258) 個のトークン (画像をコンテキストとして生成する場合) をそれぞれ BF16 または Int4 量子化レベルでエンコードする場合の GPU メモリ使用量のピーク値をプロファイリングしました。結果を以下に示します。
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
| ------------ | :---------------------------------: | :-----------------------------------: |
| BF16 | 22.60GB | 28.01GB |
| Int4 | 11.82GB | 17.23GB |
上記のスピードとメモリーのプロファイリングは、[このスクリプト](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py)を使用しています。
## ファインチューニング
現在、公式のトレーニングスクリプト `finetune.py` を提供しています。さらに、finetune.py のシェルスクリプトを提供し、finetune.py を実行することで、finetune.py を起動することができる。さらに、安心してファインチューニングを開始するためのシェルスクリプトも提供しています。このスクリプトは、[DeepSpeed](https://github.com/microsoft/DeepSpeed) および [FSDP](https://engineering.fb.com/2021/07/15/open-source/fsdp/) を使用したトレーニングをサポートします。弊社が提供するシェル・スクリプトは DeepSpeed を使用するため、事前に DeepSpeed をインストールすることをお勧めします:
学習データを準備するには、すべてのサンプルをリストにまとめ、json ファイルに保存する必要があります。各サンプルは id と会話リストで構成される辞書です。以下は 1 つのサンプルを含む単純なリストの例です:
```json
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是Qwen-VL,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg\n图中的狗是什么品种?"
},
{
"from": "assistant",
"value": "图中是一只拉布拉多犬。"
},
{
"from": "user",
"value": "框出图中的格子衬衫"
},
{
"from": "assistant",
"value": "格子衬衫
assets/mm_tutorial/Chongqing.jpeg\nPicture 2:
assets/mm_tutorial/Beijing.jpeg\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
```
VL タスクの場合、`
img_path\n{your prompt}`」として表されます。ここで、「id」は会話内の画像の位置を 1 から示します。「img_path」は ローカル ファイル パスまたは Web リンク。
座標ボックスは `
| Method | Sequence Length | |||
|---|---|---|---|---|
| 384 | 512 | 1024 | 2048 | |
| LoRA (Base) | 37.1G / 2.3s/it | 37.3G / 2.4s/it | 38.7G / 3.6s/it | 38.7G / 6.1s/it |
| LoRA (Chat) | 23.3G / 2.2s/it | 23.6G / 2.3s/it | 25.1G / 3.5s/it | 27.3G / 5.9s/it |
| Q-LoRA | 17.0G / 4.2s/it | 17.2G / 4.5s/it | 18.2G / 5.5s/it | 19.3G / 7.9s/it |
{kind=link}