![]()

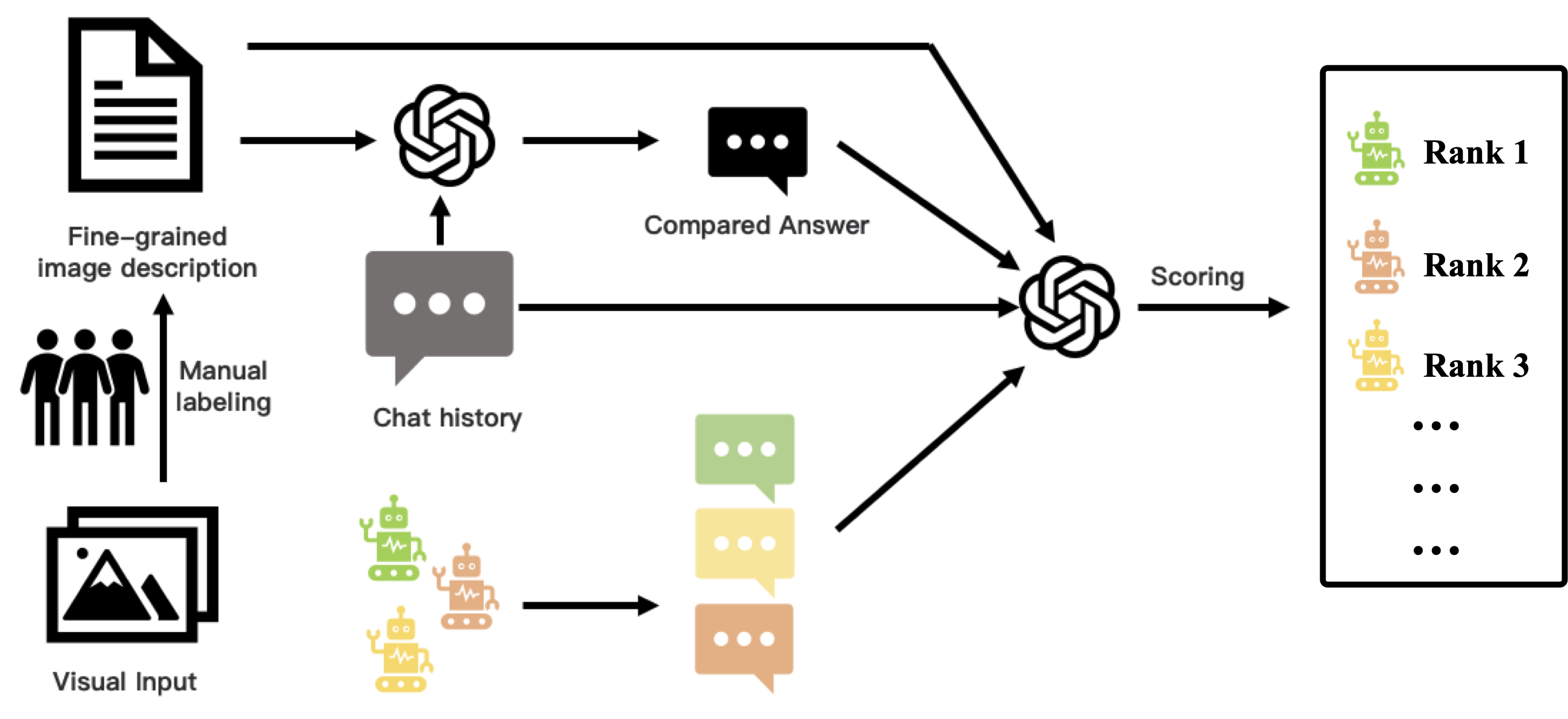
モデルの能力を 5 つの次元から総合的に評価する。上図のように、27 のサブタスクの例を示す。知覚から認知、創造性まで、難易度が上がるにつれて、モデルに求められる要件もどんどん高くなっている。現在、LVLM の機能は初期段階にある。我々のデータセットには 800 以上の質問と 27 のカテゴリーが含まれている。 ## 方法 自動評価を可能にするために、強力な LLM を判定器として適用する。画像の内容を効果的に理解するために、実際の画像入力をきめ細かいテキスト注釈に手動で置き換える。これらの注釈と対応する質問を GPT4 のような強力な LLM に入力することで、参照解答を得る。 LVLMの評価には、実際の画像と質問を入力として与え、それぞれの回答を得る。最後に、GPT4を用いて、LVLMが生成した回答を、細かいアノテーションと質問に基づいてスコアリングする。スコアリングの指示は、注釈を画像の内容とみなして、回答の有用性、関連性、正確性を評価するようモデルに要求する。評価の公平性を確保するため、各モデルの回答はGPT4の一貫した参照回答と比較されます。全問題におけるモデルの平均スコアを最終スコアとする。 解答位置の影響を排除するために、解答位置を入れ替えて2回目の採点ラウンドを行い、得られた2つのスコアの平均を計算します。このアプローチは、解答の配置によって生じるバイアスを軽減することを目的としています。
### 評価 #### 英語ベースのマルチモーダル対話における評価 | Model | Score | |---------------|-------| | PandaGPT | 488.5 | | MiniGPT4 | 531.7 | | InstructBLIP | 552.4 | | LLaMA-AdapterV2 | 590.1 | | mPLUG-Owl | 605.4 | | LLaVA | 602.7 | | Qwen-VL-Chat | 645.2 | #### 中国語ベースのマルチモーダル対話における評価 | Model | Score | |---------------|-------| | VisualGLM | 247.1 | | Qwen-VL-Chat | 401.2 |