![]()
Qwen-VL 🤖 | 🤗 | Qwen-VL-Chat 🤖 | 🤗 | Qwen-VL-Chat-Int4 🤗
WeChat | Discord | Demo | Paper | Colab | Tutorial

We release two models of the Qwen-VL series:
- Qwen-VL: The pre-trained LVLM model uses Qwen-7B as the initialization of the LLM, and [Openclip ViT-bigG](https://github.com/mlfoundations/open_clip) as the initialization of the visual encoder. And connects them with a randomly initialized cross-attention layer.
- Qwen-VL-Chat: A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multiple image inputs, multi-round question answering, and creative capabilities.
## News and Updates
* ```2023.9.25``` 🚀🚀🚀 We update Qwen-VL-Chat with more robust Chinese instruction-following ability, improved understanding of web pages and table images, and better dialogue performance (Touchstone: CN: 401.2->481.7, EN: 645.2->711.6).
* ```2023.9.12``` 😃😃😃 We now support finetuning on the Qwen-VL models, including full-parameter finetuning, LoRA and Q-LoRA.
* ```2023.9.8``` 👍👍👍 Thanks to [camenduru](https://github.com/camenduru) for contributing the wonderful [Colab](https://github.com/camenduru/Qwen-VL-Chat-colab). Everyone can use it as a local or online Qwen-VL-Chat-Int4 Demo tutorial on one 12G GPU.
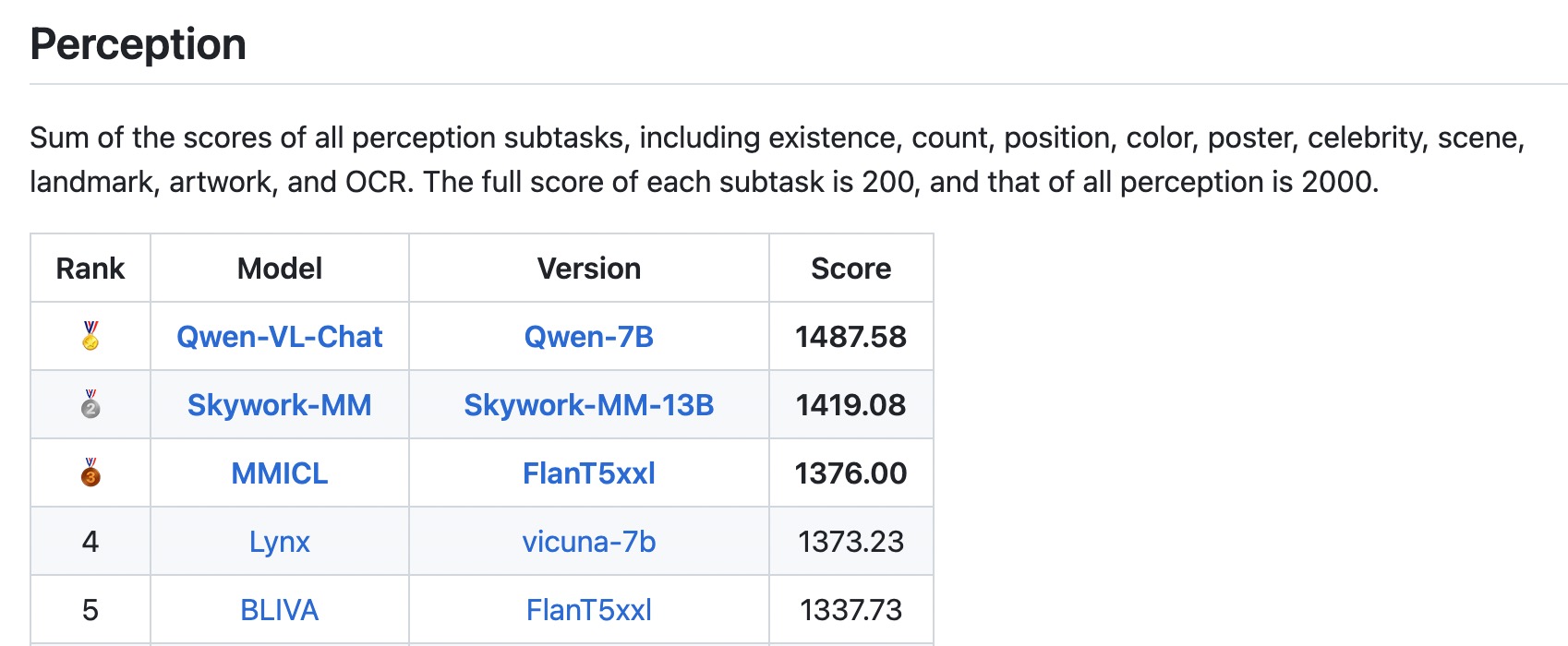
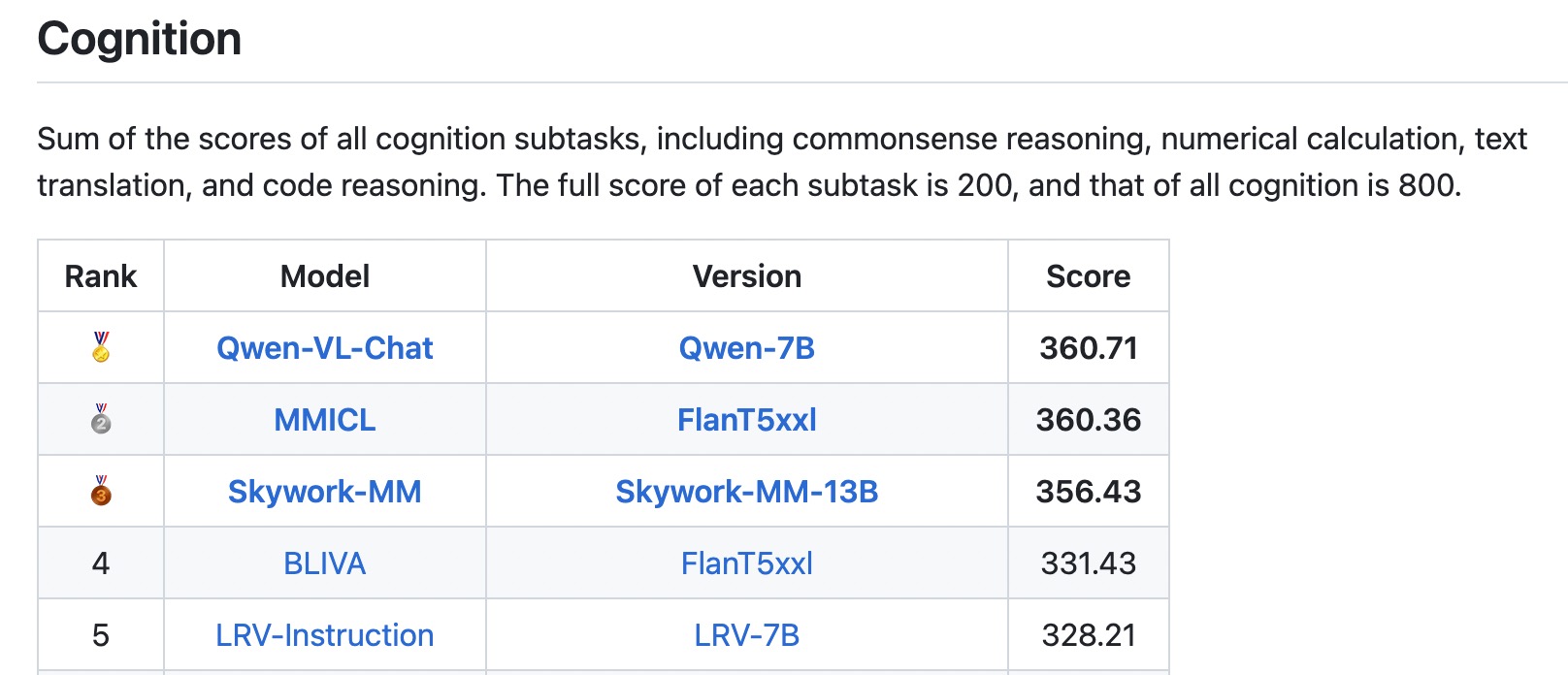
* ```2023.9.5``` 👏👏👏 Qwen-VL-Chat achieves SOTAs on [MME Benchmark](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation), a comprehensive evaluation benchmark for multimodal large language models. It measures both perception and cognition abilities on a total of 14 subtasks.
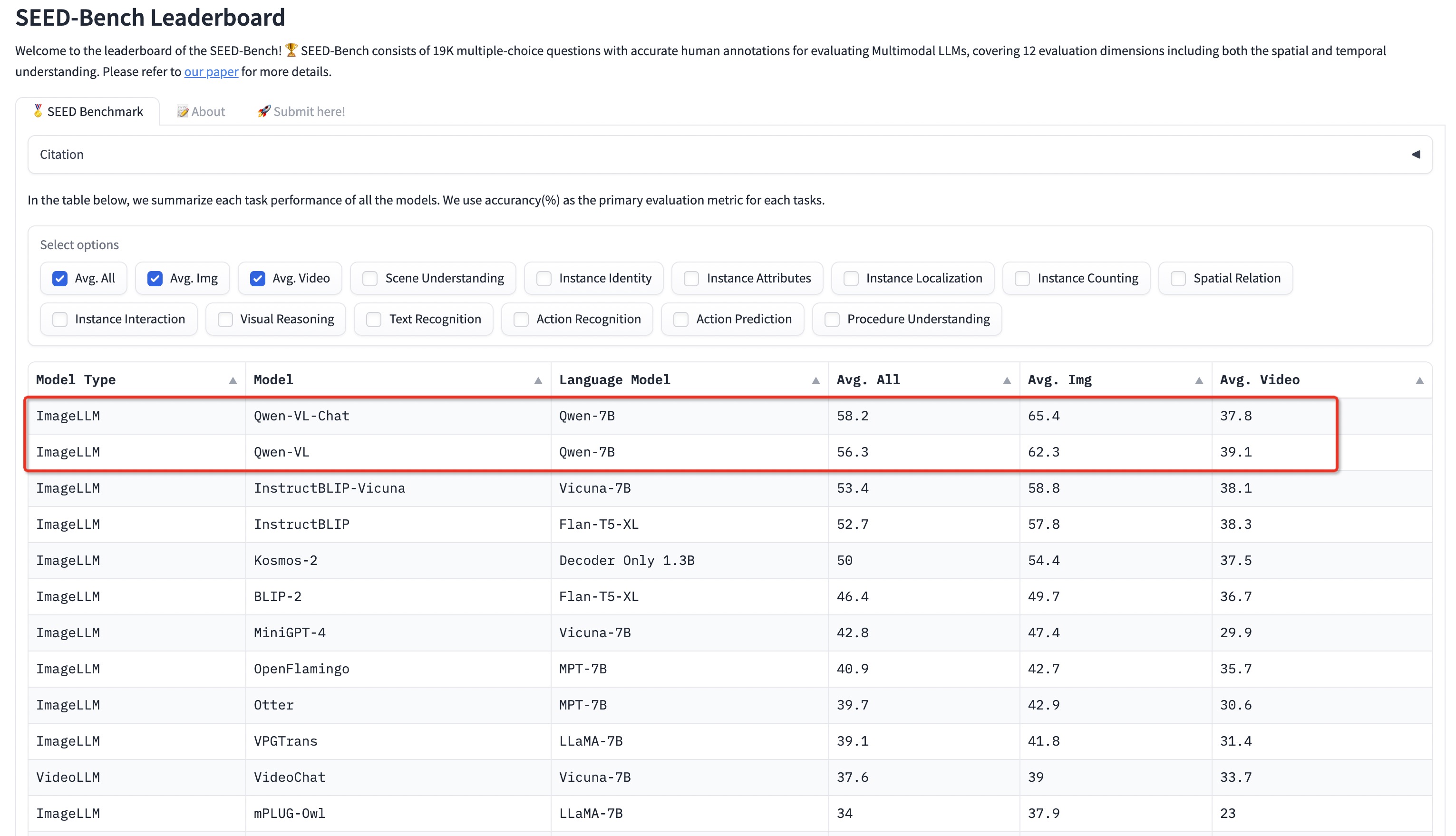
* ```2023.9.4``` ⭐⭐⭐ Qwen-VL series achieve SOTAs on [Seed-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard), a multimodal benchmark of 19K multiple-choice questions with accurate human annotations for evaluating Multimodal LLMs including both image and video understanding.
* ```2023.9.1``` 🔥🔥🔥 We release the [TouchStone](https://github.com/OFA-Sys/TouchStone) Evaluation, which is a comprehensive assessment of multimodal language models, encompassing not only basic recognition and comprehension but also extending to literary creation. By using strong LLMs as judges and converting multimodal information into text.
* ```2023.8.31``` 🌟🌟🌟 We release the Int4 quantized model for Qwen-VL-Chat, **Qwen-VL-Chat-Int4**, which requires low memory costs but achieves improved inference speed. Besides, there is no significant performance degradation on the benchmark evaluation.
* ```2023.8.22``` 🎉🎉🎉 We release both **Qwen-VL** and **Qwen-VL-Chat** on ModelScope and Hugging Face. We also provide a [paper](https://arxiv.org/abs/2308.12966) for more details about the model, including training details and model performance.
## Evaluation
We evaluated the model's abilities from three perspectives:
1. **Standard Benchmarks**: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
- Zero-shot Captioning: Evaluate model's zero-shot image captioning ability on unseen datasets;
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
2. **TouchStone**: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called [TouchStone](https://github.com/OFA-Sys/TouchStone), which is based on scoring with GPT4 to evaluate the LVLM model.
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
- The benchmark includes both English and Chinese versions.
3. **Other Multimodal Benchmarks**: We also evaluated our model's capabilities in other multimodal benchmarks:
- [MME Benchmark](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation), a comprehensive evaluation benchmark for multimodal large language models. Qwen-VL-Chat achieves SOTAs on both perception and cognition tracks.
- [Seed-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard), a multimodal benchmark of 19K multiple-choice questions with accurate human annotations for evaluating Multimodal LLMs. Qwen series achieves SOTAs on this benchmark.
The results of the evaluation are as follows:
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
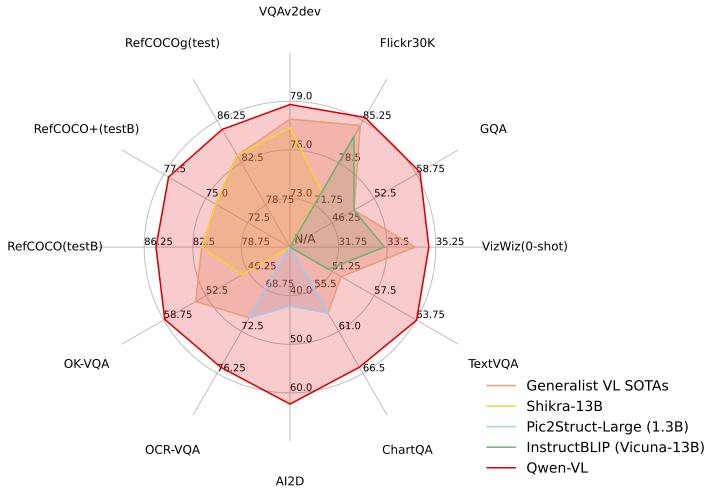
### Zero-shot Captioning & General VQA
| Model type | Model | Zero-shot Captioning | General VQA | |||||
|---|---|---|---|---|---|---|---|---|
| NoCaps | Flickr30K | VQAv2dev | OK-VQA | GQA | SciQA-Img (0-shot) |
VizWiz (0-shot) |
||
| Generalist Models |
Flamingo-9B | - | 61.5 | 51.8 | 44.7 | - | - | 28.8 |
| Flamingo-80B | - | 67.2 | 56.3 | 50.6 | - | - | 31.6 | |
| Unified-IO-XL | 100.0 | - | 77.9 | 54.0 | - | - | - | |
| Kosmos-1 | - | 67.1 | 51.0 | - | - | - | 29.2 | |
| Kosmos-2 | - | 80.5 | 51.1 | - | - | - | - | |
| BLIP-2 (Vicuna-13B) | 103.9 | 71.6 | 65.0 | 45.9 | 32.3 | 61.0 | 19.6 | |
| InstructBLIP (Vicuna-13B) | 121.9 | 82.8 | - | - | 49.5 | 63.1 | 33.4 | |
| Shikra (Vicuna-13B) | - | 73.9 | 77.36 | 47.16 | - | - | - | |
| Qwen-VL (Qwen-7B) | 121.4 | 85.8 | 78.8 | 58.6 | 59.3 | 67.1 | 35.2 | |
| Qwen-VL-Chat | 120.2 | 81.0 | 78.2 | 56.6 | 57.5 | 68.2 | 38.9 | |
| Previous SOTA (Per Task Fine-tuning) |
- | 127.0 (PALI-17B) |
84.5 (InstructBLIP -FlanT5-XL) |
86.1 (PALI-X -55B) |
66.1 (PALI-X -55B) |
72.1 (CFR) |
92.53 (LLaVa+ GPT-4) |
70.9 (PALI-X -55B) |
| Model type | Model | TextVQA | DocVQA | ChartQA | AI2D | OCR-VQA |
|---|---|---|---|---|---|---|
| Generalist Models | BLIP-2 (Vicuna-13B) | 42.4 | - | - | - | - |
| InstructBLIP (Vicuna-13B) | 50.7 | - | - | - | - | |
| mPLUG-DocOwl (LLaMA-7B) | 52.6 | 62.2 | 57.4 | - | - | |
| Pix2Struct-Large (1.3B) | - | 76.6 | 58.6 | 42.1 | 71.3 | |
| Qwen-VL (Qwen-7B) | 63.8 | 65.1 | 65.7 | 62.3 | 75.7 | |
| Specialist SOTAs (Specialist/Finetuned) |
PALI-X-55B (Single-task FT) (Without OCR Pipeline) |
71.44 | 80.0 | 70.0 | 81.2 | 75.0 |
| Model type | Model | RefCOCO | RefCOCO+ | RefCOCOg | GRIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| val | test-A | test-B | val | test-A | test-B | val-u | test-u | refexp | ||
| Generalist Models | GPV-2 | - | - | - | - | - | - | - | - | 51.50 |
| OFA-L* | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | 61.70 | |
| Unified-IO | - | - | - | - | - | - | - | - | 78.61 | |
| VisionLLM-H | 86.70 | - | - | - | - | - | - | - | ||
| Shikra-7B | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 69.34 | |
| Shikra-13B | 87.83 | 91.11 | 81.81 | 82.89 | 87.79 | 74.41 | 82.64 | 83.16 | 69.03 | |
| Qwen-VL-7B | 89.36 | 92.26 | 85.34 | 83.12 | 88.25 | 77.21 | 85.58 | 85.48 | 78.22 | |
| Qwen-VL-7B-Chat | 88.55 | 92.27 | 84.51 | 82.82 | 88.59 | 76.79 | 85.96 | 86.32 | - | |
| Specialist SOTAs (Specialist/Finetuned) |
G-DINO-L | 90.56 | 93.19 | 88.24 | 82.75 | 88.95 | 75.92 | 86.13 | 87.02 | - |
| UNINEXT-H | 92.64 | 94.33 | 91.46 | 85.24 | 89.63 | 79.79 | 88.73 | 89.37 | - | |
| ONE-PEACE | 92.58 | 94.18 | 89.26 | 88.77 | 92.21 | 83.23 | 89.22 | 89.27 | - | |
#### SEED-Bench [SEED-Bench](https://huggingface.co/spaces/AILab-CVC/SEED-Bench_Leaderboard) is a multimodal benchmark of 19K multiple-choice questions with accurate human annotations for evaluating Multimodal LLMs, covering 12 evaluation dimensions including both **image** and **video** understanding. See more details on [HERE](eval_mm/seed_bench/EVAL_SEED.md). Qwen-VL and Qwen-VL-Chat achieve SOTAs on this benchmark.
## Requirements
* python 3.8 and above
* pytorch 1.12 and above, 2.0 and above are recommended
* CUDA 11.4 and above are recommended (this is for GPU users)
## Quickstart
Below, we provide simple examples to show how to use Qwen-VL and Qwen-VL-Chat with 🤖 ModelScope and 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
```bash
pip install -r requirements.txt
```
Now you can start with ModelScope or Transformers. More usage aboue vision encoder, please refer to the [tutorial](TUTORIAL.md).
#### 🤗 Transformers
To use Qwen-VL-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 1st dialogue turn
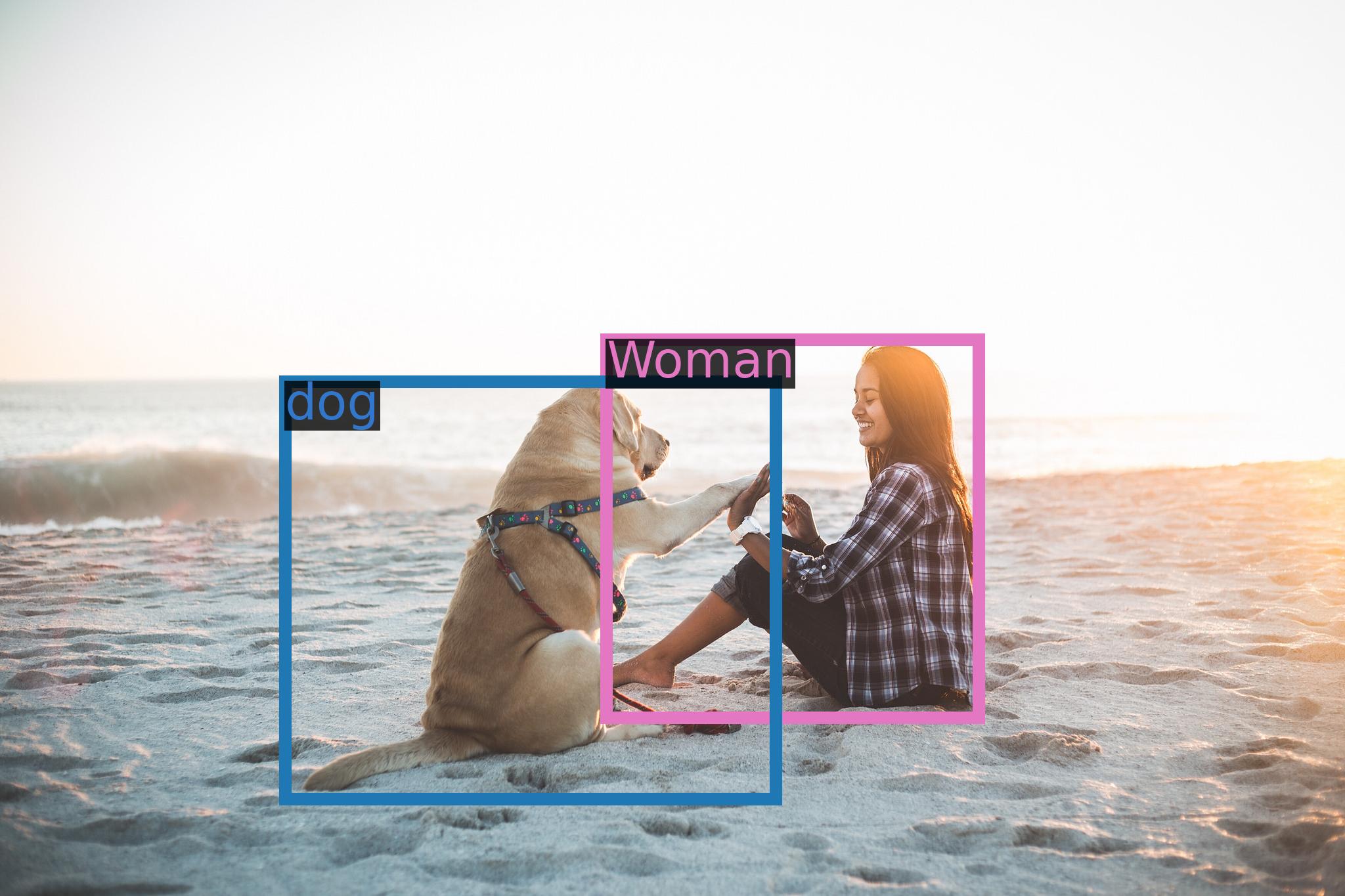
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# 击掌

In the event of a network issue while attempting to download model checkpoints and codes from HuggingFace, an alternative approach is to initially fetch the checkpoint from ModelScope and then load it from the local directory as outlined below:
```python
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-VL')
model_dir = snapshot_download('qwen/Qwen-VL-Chat')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="cuda",
trust_remote_code=True
).eval()
```
#### 🤖 ModelScope
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
```python
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
if not hasattr(tokenizer, 'model_dir'):
tokenizer.model_dir = model_dir
# use bf16
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# use auto
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation (No need to do this if you are using transformers>=4.32.0)
# model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 1st dialogue turn
# Either a local path or an url between Running Qwen-VL
Running Qwen-VL pretrained base model is also simple.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL", device_map="cuda", trust_remote_code=True).eval()
# Specify hyperparameters for generation (No need to do this if you are using transformers>4.32.0)
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': 'Generate the caption in English with grounding:'},
])
inputs = tokenizer(query, return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
response = tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
print(response)
# https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpegGenerate the caption in English with grounding: Woman
tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# "击掌"
## Quantization
### Usage
We provide a new solution based on [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ), and release an Int4 quantized model for Qwen-VL-Chat, Qwen-VL-Chat-Int4 [Click here](https://huggingface.co/Qwen/Qwen-VL-Chat-Int4), which achieves nearly lossless model effects but improved performance on both memory costs and inference speed.
Here we demonstrate how to use our provided quantized models for inference. Before you start, make sure you meet the requirements (e.g., torch 2.0 and above, transformers 4.32.0 and above, etc.) and install the required packages:
```bash
pip install optimum
git clone https://github.com/JustinLin610/AutoGPTQ.git & cd AutoGPTQ
pip install -v .
```
If you meet problems installing `auto-gptq`, we advise you to check out the official [repo](https://github.com/PanQiWei/AutoGPTQ) to find a wheel.
Then you can load the quantized model easily and run inference as same as usual:
```python
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-VL-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
# Either a local path or an url between tags.
image_path = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
response, history = model.chat(tokenizer, query=f'
{image_path}这是什么', history=None)
print(response)
```
### Performance
We illustrate the model performance of both BF16 and Int4 models on the benchmark **[TouchStone](https://github.com/OFA-Sys/TouchStone)**, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
| Quantization | ZH | EN |
| ------------ | :--------: | :-----------: |
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
### Inference Speed
We measured the average inference speed (tokens/s) of generating 1792 (2048-258) and 7934 (8192-258) tokens with the context of an image (which takes 258 tokens) under BF16 precision and Int4 quantization, respectively.
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
| ------------ | :-----------------: | :-----------------: |
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4.
### GPU Memory Usage
We also profile the peak GPU memory usage for encoding 1792 (2048-258) tokens (including an image) as context (and generating single token) and generating 7934 (8192-258) tokens (with an image as context) under BF16 or Int4 quantization level, respectively. The results are shown below.
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
| ------------ | :---------------------------------: | :-----------------------------------: |
| BF16 | 22.60GB | 28.01GB |
| Int4 | 11.82GB | 17.23GB |
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py).
## Finetuning
Now we provide the official training script, `finetune.py`, for users to finetune the pretrained model for downstream applications in a simple fashion. Additionally, we provide shell scripts to launch finetuning with no worries. This script supports the training with DeepSpeed and FSDP. The shell scripts that we provide use DeepSpeed, and thus we advise you to install DeepSpeed before you start:
```bash
pip install deepspeed
```
### Data preparation
To prepare your training data, you need to put all the samples into a list and save it to a json file. Each sample is a dictionary consisting of an id and a list for conversation. Below is a simple example list with 1 sample:
```json
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是Qwen-VL,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg\n图中的狗是什么品种?"
},
{
"from": "assistant",
"value": "图中是一只拉布拉多犬。"
},
{
"from": "user",
"value": "框出图中的格子衬衫"
},
{
"from": "assistant",
"value": "格子衬衫
assets/mm_tutorial/Chongqing.jpeg\nPicture 2:
assets/mm_tutorial/Beijing.jpeg\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]
```
For the VL tasks, there are special tokens that are used, including `
img_path\n{your prompt}`, where `id` indicates the position of the image in the conversation, starting from 1. The "img_path" can be a local file path or a web link.
The coordinate box is expressed as `
| Method | Sequence Length | |||
|---|---|---|---|---|
| 384 | 512 | 1024 | 2048 | |
| LoRA (Base) | 37.1G / 2.3s/it | 37.3G / 2.4s/it | 38.7G / 3.6s/it | 38.7G / 6.1s/it |
| LoRA (Chat) | 23.3G / 2.2s/it | 23.6G / 2.3s/it | 25.1G / 3.5s/it | 27.3G / 5.9s/it |
| Q-LoRA | 17.0G / 4.2s/it | 17.2G / 4.5s/it | 18.2G / 5.5s/it | 19.3G / 7.9s/it |
{kind=link}